Two-layered DCT/Sparse representation for video coding
- 2015년 11월 7일
- 1분 분량

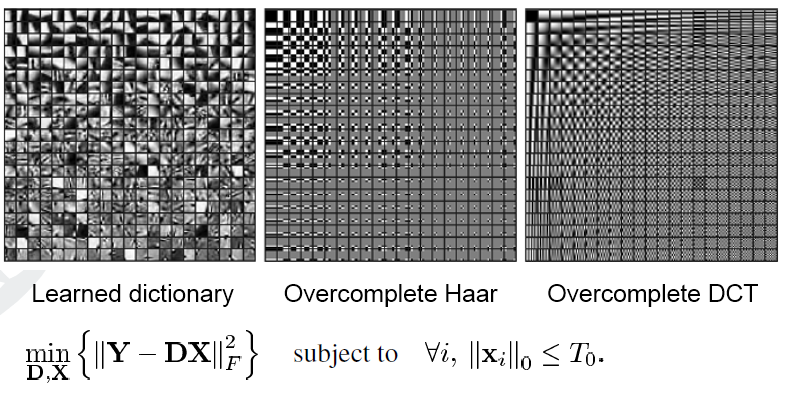

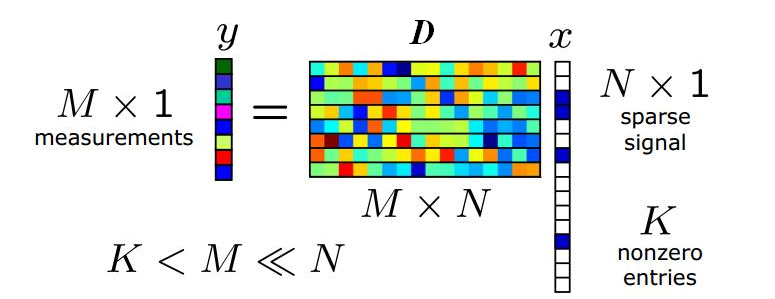

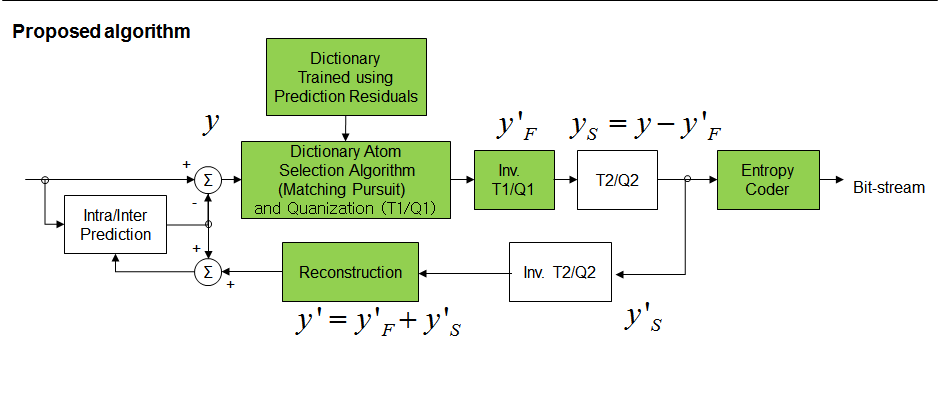

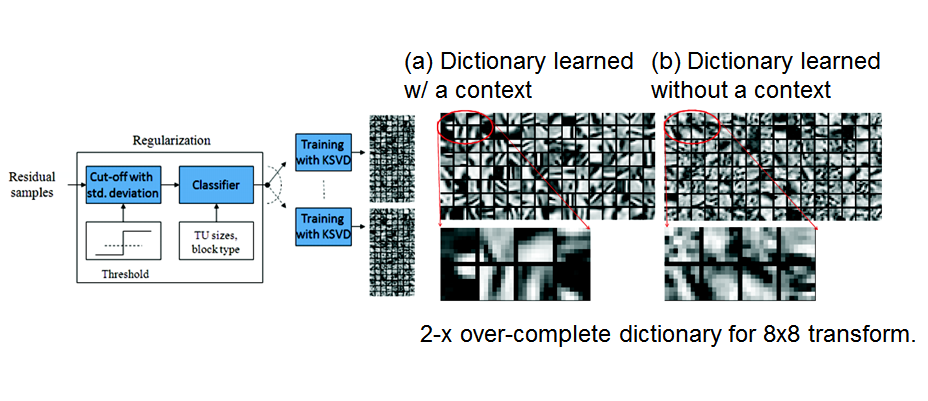



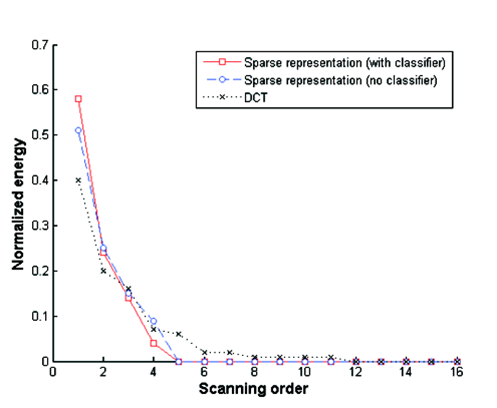




We propose a cascaded sparse/DCT (S/DCT) two-layer representation of prediction residuals, and implement this idea on top of the state-of-the-art high efficiency video coding (HEVC) standard. First, a dictionary is adaptively trained to contain featured patterns of residual signals so that a high portion of energy in a structured residual can be efficiently coded via sparse coding. It is observed that the sparse representation alone is less effective in the R-D performance due to the side information overhead at higher bit rates. To overcome this problem, the DCT representation is cascaded at the second stage. It is applied to the remaining signal to improve coding efficiency.
댓글